Image Classification, Search and Sorting
[link to COREL categorization] basic-level
categories sorted according to percentage correct
[link to COREL category labels] how we categorized the COREL image classes
[pdf] 80-citation manuscript
[talk]
slides about the categorization system
The Challenge: Visual image classification is the assignment of a given image to a
category such as ‘chair’, ‘animal’, ‘street scene, and so on. This assignment
is difficult because categories bear a lot of structural variability, for
instance different chairs appear with varying geometry. This geometrical
variability is underestimated and not properly expressed in any previous and
present classification approach.
Method: I therefore
pursue a classification system, in which an image is firstly decomposed into a large number of parameters
describing contours and areas. For instance, contour vectors describe aspects
such as length, orientation, curvature, smoothness, fuzziness, contrast and
degree of isolation in a structure.
Evaluation: The decomposition was evaluated on the COREL draw and the Caltech 101
collection. For each I obtained an average of 12 percent correct categorization,
using a simple histogramming approach! Using a vector-based image search, I
obtained an average of 22 and 28 percent correct categorization (for the first
100 images). That is extremely promising!
Long-term goal: To obtain perfect categorization, I now need to span the appropriate
multi-dimensional space with those parameters, which allows forming abstract
category representations.
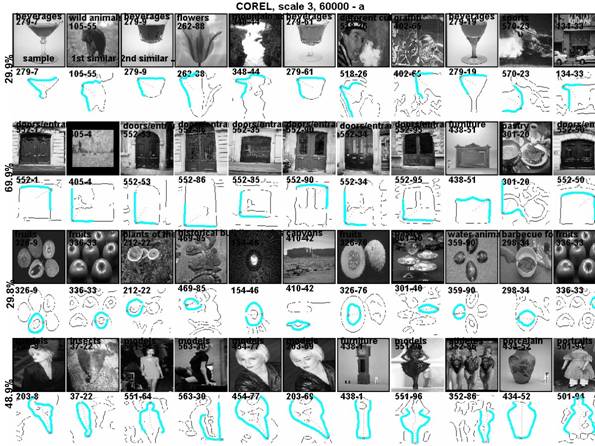
Evaluation Examples: Here are some example searches (using all 60000 COREL images),
specifically similarity-based image searches of which the similar images were
basic-level categorized [without
color information!]:


Pretty good, but obviously not perfect yet. However that was only the
beginning (this was only a histogramming search, without the explicit matching
of individual contours). The following shows how specific contours can be (individual contour matching):

And this demonstrates
how specific areas (relation between
two contours) can be:
The method is
obviously highly potential but now requires a clever learning procedure.
The long-term goal is
of course to build a complete scene-understanding system.
Image sorting according to
aspects, length, curvature, contrast,…

More similarity-based image
search: The first one is the sample image, the remaining ones are the
detected similar ones (without categorization though):

The following are learned category-specific contours for the Caltech
collection, with which I obtained a search performance of 28 percent in
average:

Conclusion: The parameterization is very detailed and can
obviously be used for categorization and image search to some extent. But now I
need to perform more grouping and abstraction.